TABLE OF CONTENT
PAGE 1: ABOUT CORALI-LANG BENCHMARK
PAGE 2: GEMINI 3 FLASH PREVIEW
PAGE 3: GEMINI 3.1 PRO PREVIEW
PAGE 4: GEMMA 4 26B A4B
PAGE 5: GEMMA 4 31B
PAGE 6: GLM-5
PAGE 7: CLAUDE SONNET 4.6
PAGE 8: CLAUDE OPUS 4.6
PAGE 9: GPT-5.4
PAGE 10: CLAUDE HAIKU 4.5
PAGE 11: GEMINI 3.1 FLASH LITE PREVIEW
PAGE 12: QWEN 3 NEXT 80B THINKING
PAGE 13: DEEPSEEK V3.2
PAGE 14: QWEN 3 NEXT 80B INSTRUCT
PAGE 15: GPT-5.4 NANO
PAGE 16: GPT-5.4 MINI
PAGE 17: CONCLUSIONS
CORALI-LANG BENCHMARK

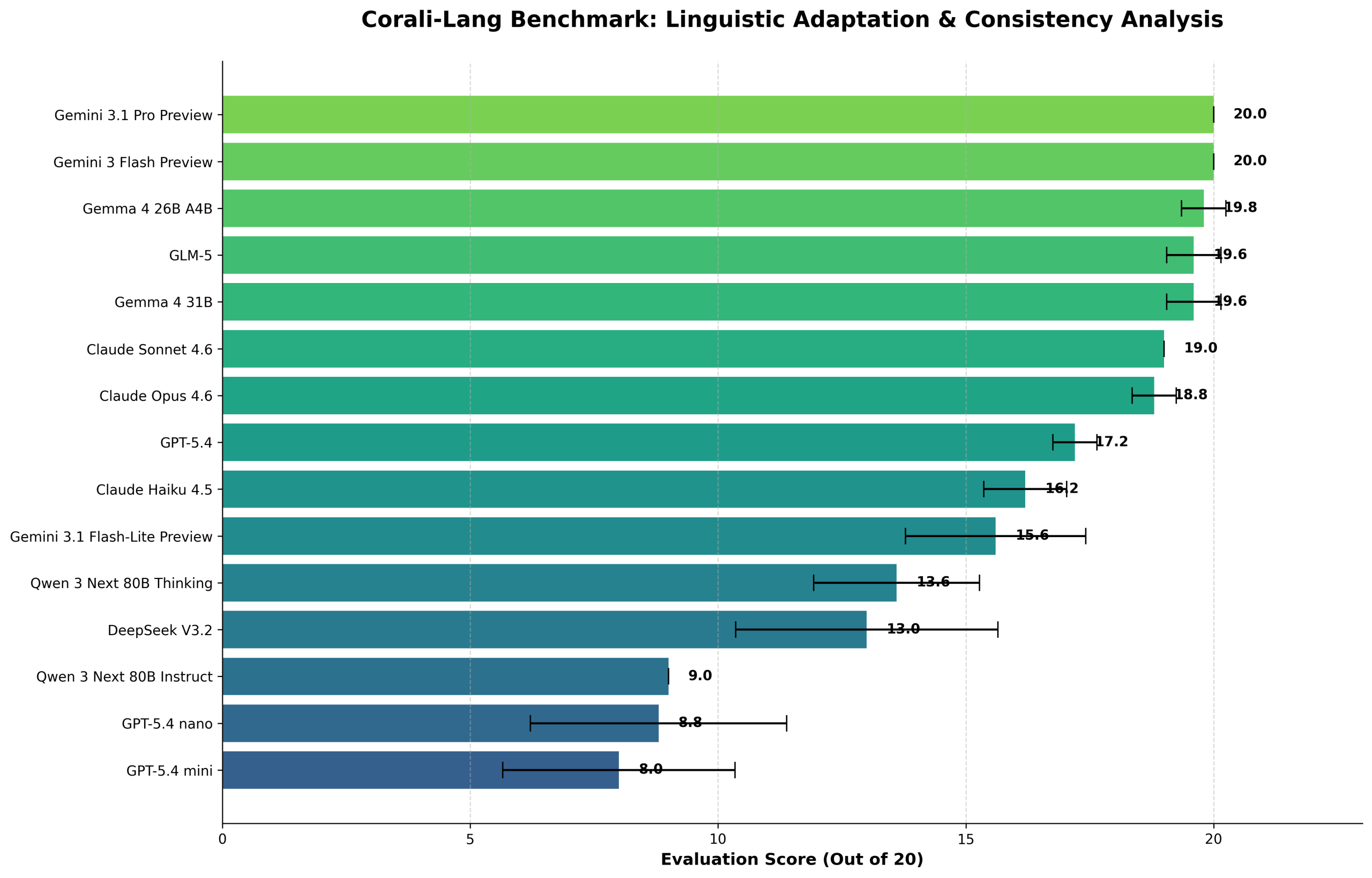
In this post, I’ll discuss the Corali-Lang Benchmark results in more depth. This benchmark was created for a Kaggle competition: Measuring Progress Toward AGI – Cognitive Abilities.
The writeup can be found here. The writeup includes a link to the Corali-Lang Benchmark, along with five tasks and an Excel file containing the benchmark results. The data in the Excel file is taken from the task output data in JSON format. To make it easier to read and analyze, I’ve combined it into a single Excel file to analyze each model’s responses. By understanding the model’s responses, we can identify the model’s strengths, weaknesses and why it could fail.
I’ll discuss the model’s strengths and weaknesses in detail on their respective pages, along with screenshots of the results in the Excel file.