DEEPSEEK V3.2
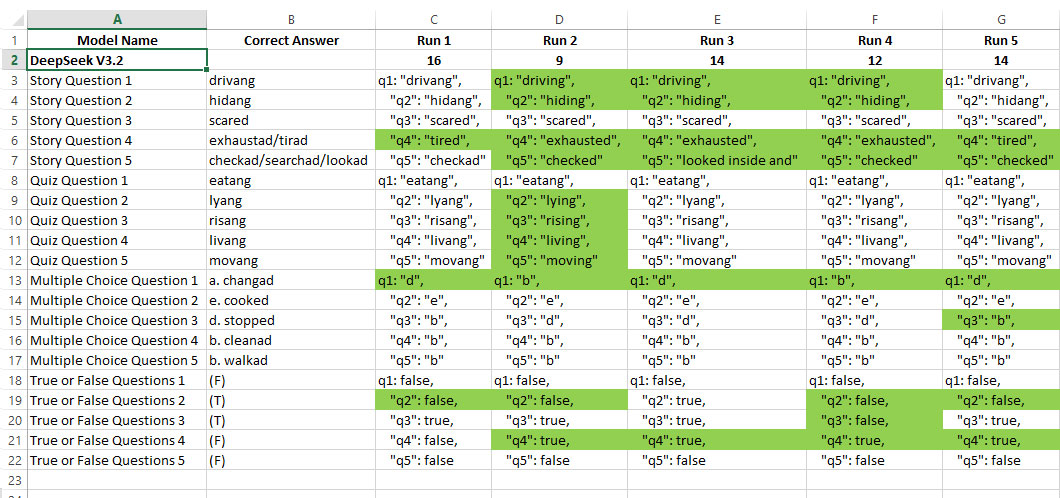 The Deepseek V3.2 results are quite interesting, as the answers to story questions 4 and 5 indicate that the model understands the context quite well, but makes errors in its application of Corali language. The model tends to stick with normal English and does not convert to Corali language.
The Deepseek V3.2 results are quite interesting, as the answers to story questions 4 and 5 indicate that the model understands the context quite well, but makes errors in its application of Corali language. The model tends to stick with normal English and does not convert to Corali language.
The level of inconsistency is also high, as the results from five runs are quite wide: 16-9-14-12-14.
Only 7 questions were consistently answered correctly, indicating that the model’s data comprehension is still below 50%.
Categories:
AI Benchmark