GPT-5.4 MINI
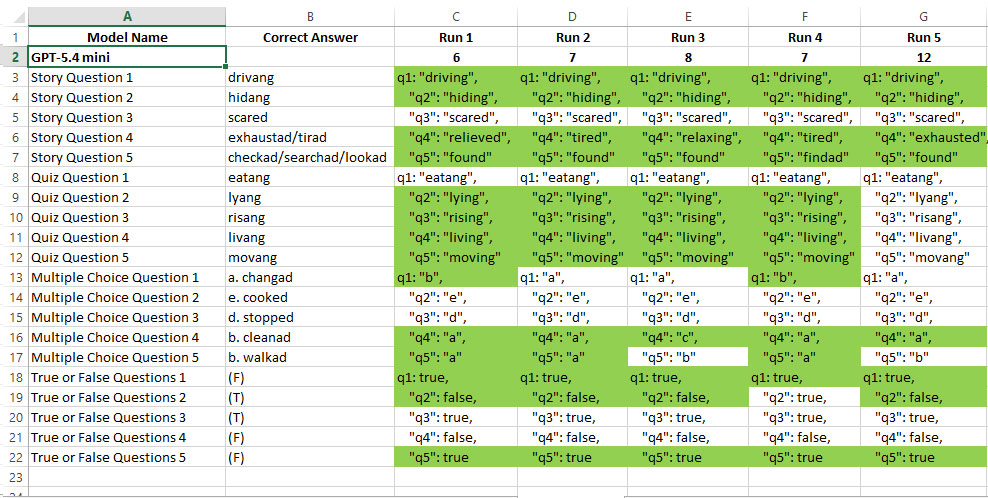 The results of the GPT-5.4 mini model’s responses indicate that this model has a better and more consistent understanding of context compared to GPT-5.4 nano. Perhaps GPT-5.4 nano was luckier when guessing, so its score was higher than GPT-5.4 mini which was consistent with wrong answers.
The results of the GPT-5.4 mini model’s responses indicate that this model has a better and more consistent understanding of context compared to GPT-5.4 nano. Perhaps GPT-5.4 nano was luckier when guessing, so its score was higher than GPT-5.4 mini which was consistent with wrong answers.
However, it is still very weak in applying new patterns (Corali language), so it tends to stick to normal English. Weaknesses in word choice are also quite consistent, as seen in the answers to story question number 5.
Categories:
AI Benchmark