CLAUDE HAIKU 4.5
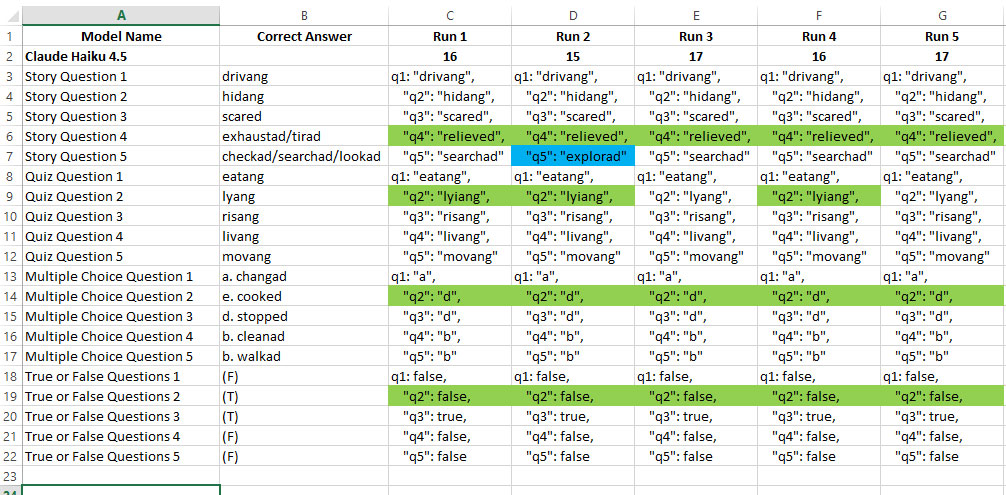 The results of Claude Haiku 4.5 show that the model made quite a few errors in understanding the context.
The results of Claude Haiku 4.5 show that the model made quite a few errors in understanding the context.
The answer “Relieved” proves that the model failed to understand Corali language. Corali was the speaker, so even if the context was incorrect, Corali’s answer would use -ad, i.e., “Relievad.” This answer was repeated five times, indicating that the model’s understanding was indeed flawed, not coincidental.
The answers to multiple-choice question number 2 and true-or-false question number 2 also demonstrate that the model failed to understand that Coral, not Corali, was speaking. Therefore, the correct answer is to use normal English, not Corali’s.
The answer “Explorad” is still acceptable, although not quite accurate. Meanwhile, the answer “Lyiang” indicates that the model still fails to apply the Corali language.
The strength of this model
– can understand long contexts, unfazed by misleading Coral’s fashion descriptions,
– can learn a new language: Corali language without being fixated on English,
– can absorb data from narratives, not just explicit rules
The weakness of this model
– make mistakes when understanding the context
– can read Corali language patterns but still inconsistent during application to other English words