CLAUDE OPUS 4.6
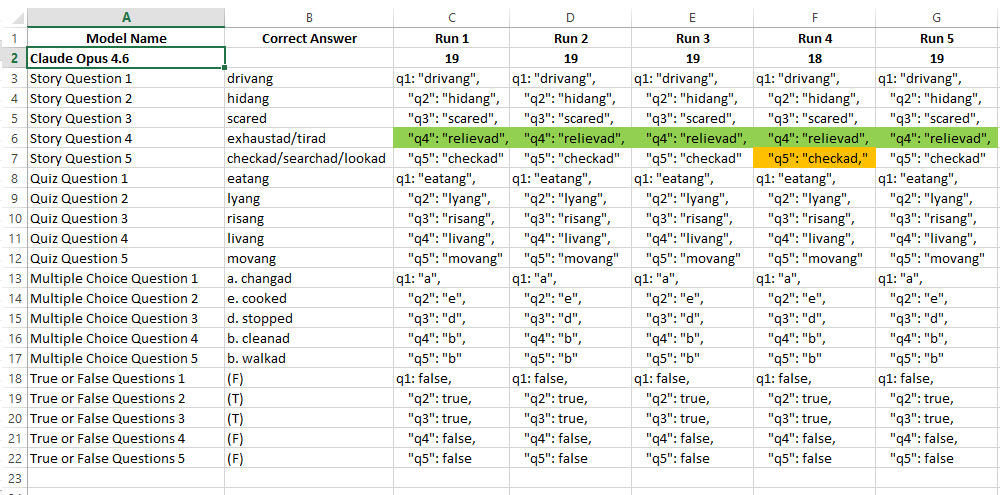 When I saw the benchmark results without detailed answers, I wondered why Claude Sonnet 4.6 outperformed Claude Opus 4.6. It turned out that both models were roughly equally strong, making errors in understanding the same context, namely story problem number 4. However, the model made a mistake when sending the answer “Checkad,” with a comma, which the system considered incorrect, even though the answer was correct.
When I saw the benchmark results without detailed answers, I wondered why Claude Sonnet 4.6 outperformed Claude Opus 4.6. It turned out that both models were roughly equally strong, making errors in understanding the same context, namely story problem number 4. However, the model made a mistake when sending the answer “Checkad,” with a comma, which the system considered incorrect, even though the answer was correct.
When I entered these results, I would mark the incorrect answers with the total correct answers and planned to edit the model’s answers by removing the JSON formatting.
However, when I checked the model’s answers, I barely noticed the model’s error (the comma), so I decided to keep the JSON formatting to catch unexpected errors like this one.
The strength of this model
– can understand long contexts, unfazed by misleading Coral’s fashion descriptions,
– can learn a new language: Corali language without being fixated on English,
– can absorb data from narratives, not just explicit rules
– can read Corali language patterns well and apply them to other English words
The weakness of this model
– make mistakes when understanding the context